前言#
JS的正则表达式有两种声明方法,一种是构造函数 var reg = new RegExp(pattern, flag);,另一种是字面量 var reg = / pattern / flag,其中字面量表示法是用斜杠来分割正则表达式。
在 JS 中斜杠/表示除法,正则表达式,反斜杠 \ 一般用来转义,Linux 中斜杠 / 是路径分隔符, Windows 中反斜杠 \ 是路径分隔符,要区分正斜杠和反斜杠只要记住正斜杠是撇,反斜杠是捺就行了。不过我很好奇字面量表示法表示正则表达式的时候,JS 引擎是如何分析这个字面量的,斜杠有可能是除法、正则或者单纯就是一个字符,虽然是编译原理的知识,不过我还是去了解一下词法分析中的 token。
词法分析#
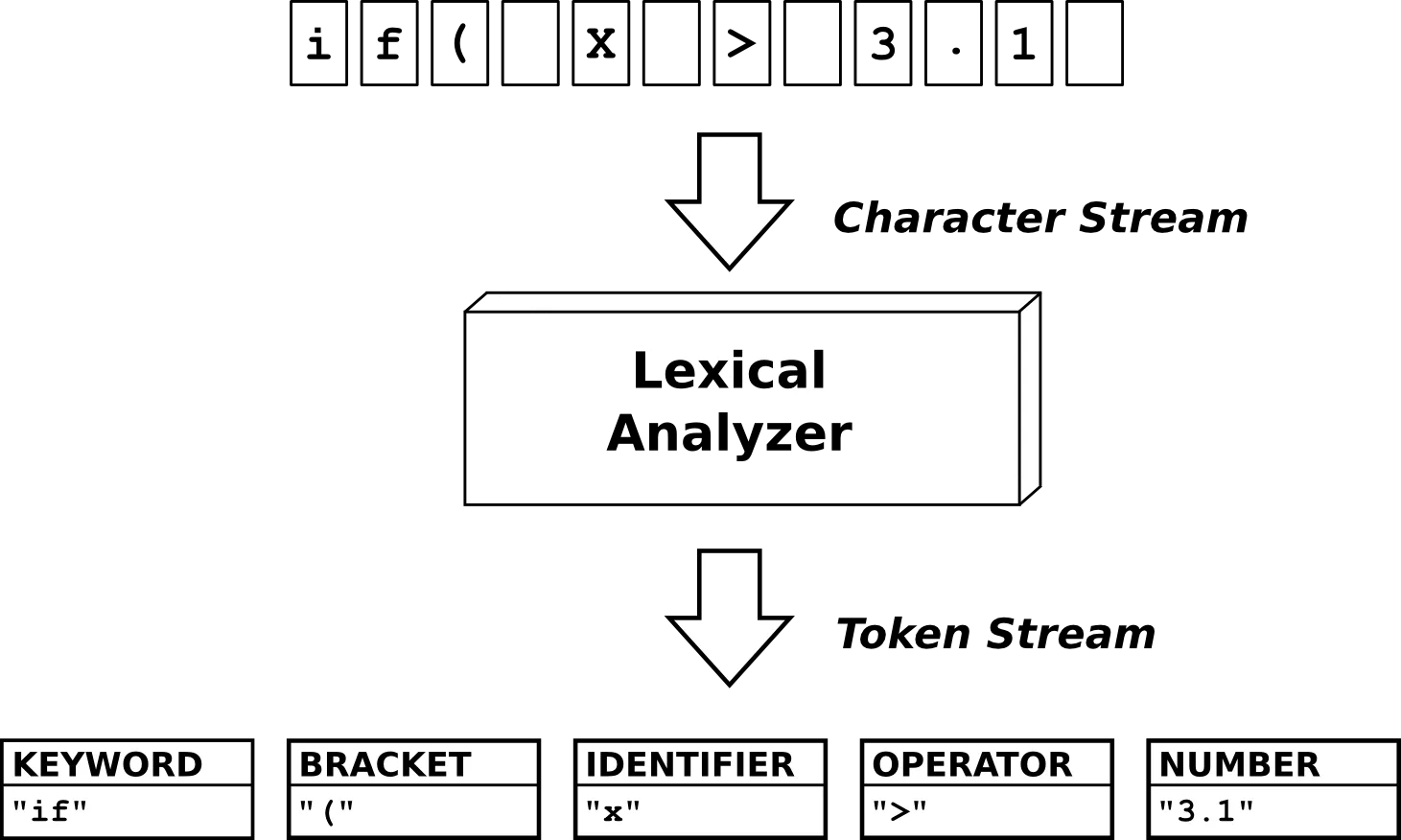
词法分析是编译过程的第一步工作,将字符流转换为单词序列,输出到中间文件中,这个中间文件将会作为语法分析程序的输入,进行下一步工作。
我们写的程序在形式上也只是有限个字符的排列,不同的语言对于排列的规则都有不同的约束,就是为了让词法分析器能够按照这个规则来对我们所写的源代码进行分析,分析的第一步就是词法分析,将字符流转换为编程语言中不可再分的单词序列,识别输入文件中的关键字、分隔符、标识符、数字、运算符、注释等。大小写不敏感,字母为 a~z, A~Z,数字为 0~9。
token#
token 中文好像翻译为标记,是一个字符串,也是构成源代码的最小单位,从输入字符流中生成标记的过程叫作标记化( tokenization ),在这个过程中,词法分析器还会对标记进行分类。编译器会从左到右扫描我们的源代码,将其中的字符流分割成一个一个的 token。
token 类别#
| Token Key | Token Value | | :----------------: | :----------------------------------: | -------- | | Space | 空格 | | Separator | 分隔符( ;,{,},(,) ) | | single-ch operator | 单字符运算符( =,+,-,*,/,%,;, | , :,!) | | two-ch operator | 双字符运算符(:=,!=,) | | num | 数字 | | less equal | <= | | NE | <> | | less than | < | | greater equal | >= | | greater than | > | | reserved word | 保留字 | | identifier | 标识符 | | string | 字符串 | | comment | 注释(单行、多行) | | error | 一些错误情况,例如数字开头的字符串 | | other | 其他符号(换行、制表等) |
标记化#
比如 sum = 3 + 2; 经过标记化后会得到
| 语素 | 标记类型 |
|---|---|
| sum | 标志符 |
| = | 赋值操作符 |
| 3 | 数字 |
| + | 加法操作符 |
| 2 | 数字 |
| ; | 语句结束 |
标记经常使用正则表达式进行定义,语法分析器读取输入字符流、从中识别出语素、最后生成不同类型的标记。其间一旦发现无效标记,便会报错。
总结#
对编译原理一窍不通,只是在写代码的过程中经常好奇编译器或者解释器是如何理解这些字符的,好奇心也经常害自己钻进牛角尖,特别是在知识储备严重不足的情况下,不过好奇心也是学习知识的动力,能够分析出当前哪些问题是以自己目前的能力能够理解和解决的尤为重要,把精力花在当前的能力无法触及的领域会浪费大量时间。本文只是自己搜索的一些资料的总结,可能理解有很多错误之处。